
关于如何自动从多伦对话中自动停止
解决方法:维护状态机制!
具体工作思路:
设置一个状态机制来跟踪对话的进度和判断收集到的信息是否足够。
判断收集的信息是足够主要是通过判断对话中是否包含必须收集信息点位,如果包含必须收集点位则认为收集信息足够。我们通过判断必须信息收集点位来实时更新信息收集进度,这个信息收集的进度我们通过设置一个状态机制来显示。在问答的循环过程中,我们不断检查信息收集的进度和更新信息收集的进度的过程被称之为维护状态机制。
维护状态机制工作流程:
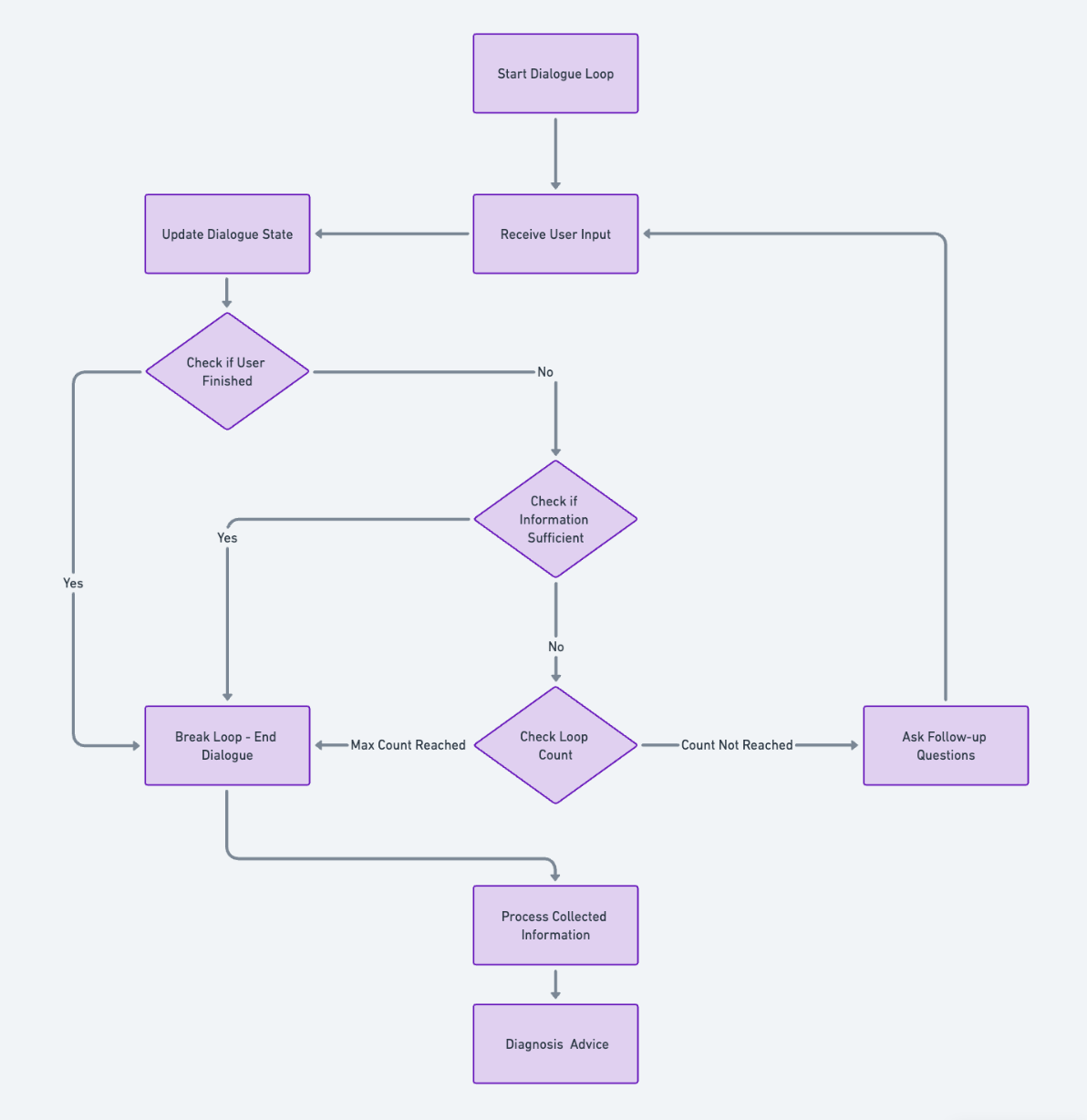
通过维护一个状态机制来跟踪对话的进度和收集到的信息是否足够的伪代码思路展示
1 | # 初始化状态 |
必要收集点位
1 | # 必须收集的信息点 |
对必要收集信息的点位归纳
主诉(Chief Complaint): 病人描述最关心的症状或病症,这是问诊的起点。
症状特点:
- 性质: 症状是急性还是慢性的?是阵发性还是持续性的?
- 位置: 症状发生在身体的什么部位?
- 程度: 症状轻重程度,如疼痛的程度。
- 时间: 症状发生的时间、持续的周期或频率。
既往史和家族史: 过去的健康问题和家族中是否有类似的健康问题。
这里解释一下维护状态和必须点位分类的关系:
维护状态{必须收集点位的分类}
我们对必须收集信息点位进行分类来生成维护状态的检查点
1 | # symptoms_collected 类: |
维护状态的检查规则:
dialogue_state里symptoms_collected 类为必须检查点,剩余条件满足一个即可使得check_if_sufficient_information_collected()返回为true
必须收集点位类的判断规则:
symptoms_collected 类中,Symptoms是必须检查项,剩余条件满足一个即可使得必须收集点位的分类设置为true
将input分类为必须信息收集点位类的工作流程图:
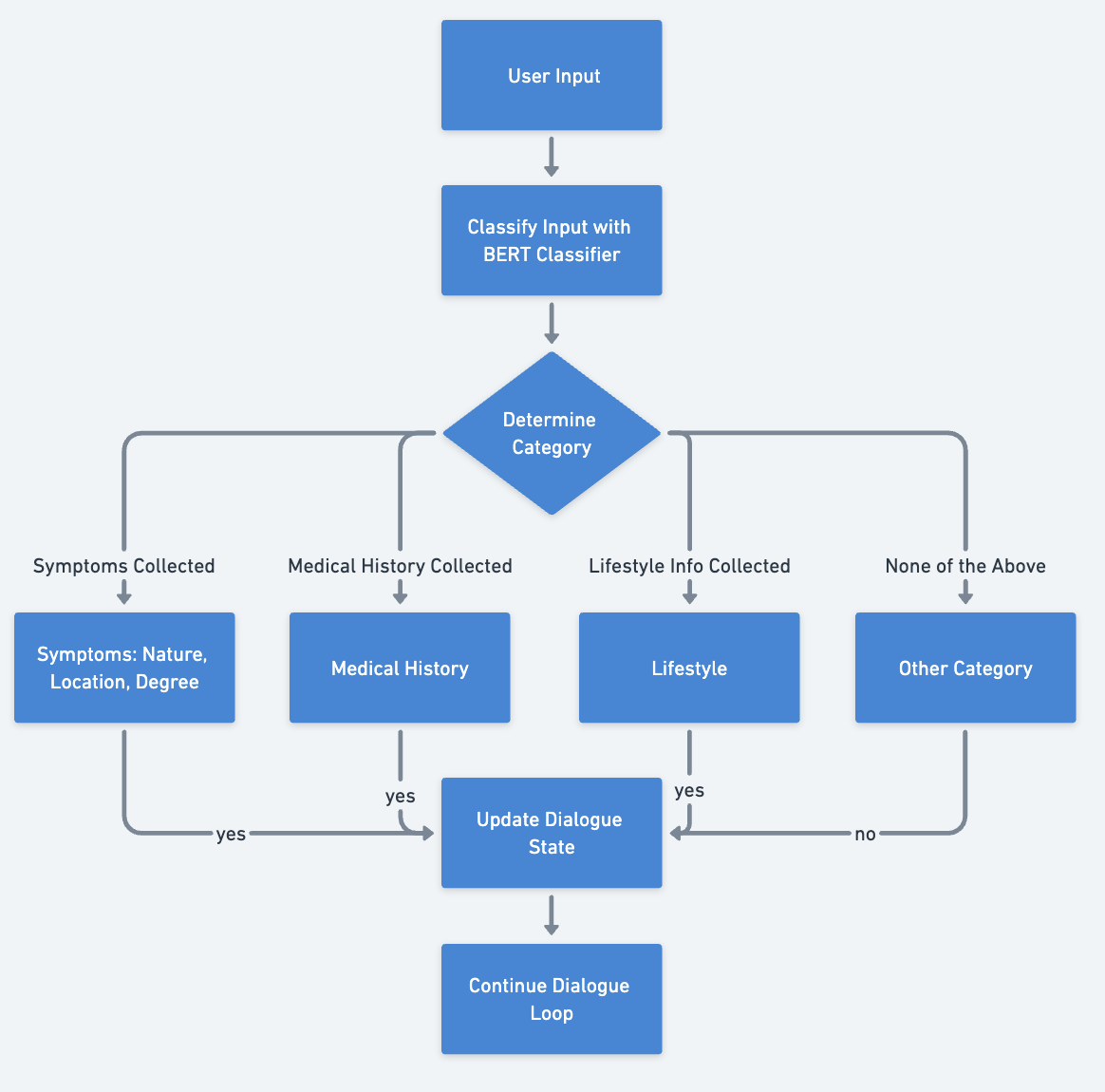
这里使用百度飞浆开源的医疗bert分类器,代码实现案列
“这里只是提出一个分类器bert的实现思路,和辅助可行性证明。” 实验代码来自:zxh
思路:
我们定义了一个schema列表,包含了13个医疗意图的类别,如病情诊断、治疗方案等。之后使用bert模型进行zero_shot_text_classification,即零样本文本分类任务,传入schema作为候选类别然后,使用input函数获取用户输入的问题,将空格和问号替换为逗号,然后使用split函数将问题分割为多个子句,存储在列表中。接着,打印列表,显示分割后的子句。最后,对于列表中的每个子句,输入bert模型得到分类结果和可信度,即每个类别的概率分布。我们对这些结果进行加权平均,得到了对用户问题意图的整体理解。
1 | from pprint import pprint |
output
1 | ['我的头有些痛', '导致我的心情很不好', '你有什么治疗建议吗', '今天天气怎么样'] |