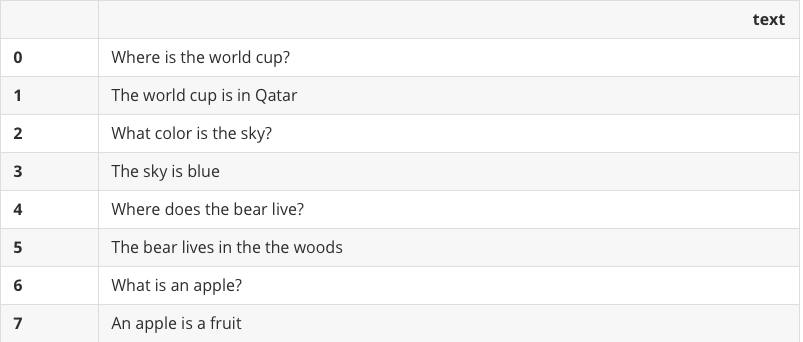
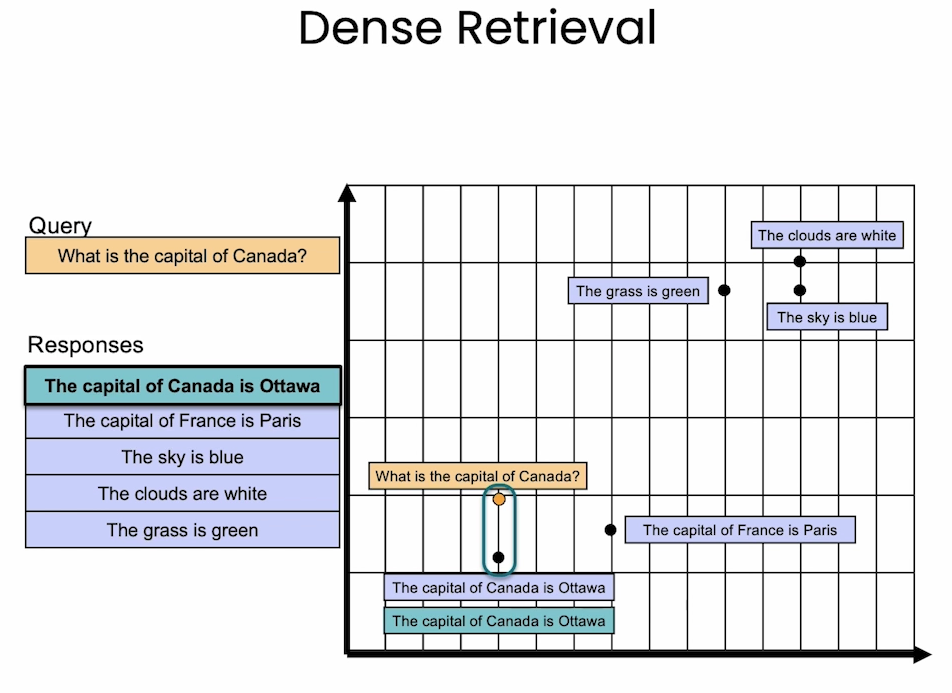
sentences = pd.DataFrame({ 'text':[ 'Where is the world cup?', 'The world cup is in Qatar', 'What color is the sky?', 'The sky is blue', 'Where does the bear live?', 'The bear lives in the the woods', 'What is an apple?', 'An apple is a fruit', ] }) sentences
# 便利wiki_articles数据中的每一行的emb元素存储在第一个d中,d表示每一行的['emb']是一个二维向量数组,再次便利每一个emb中的每一个向量元素,存储在第二个d中 # 并使用np.array将其转换为二维数组 embeds = np.array([d for d in wiki_articles['emb']])
# AnnoryIndex ANN(Aproximate Nearest Neighbors,ANN) 近似最邻近搜索 from annoy import AnnoyIndex import numpy as np import pandas as pd import re
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
text = """ Interstellar is a 2014 epic science fiction film co-written, directed, and produced by Christopher Nolan. It stars Matthew McConaughey, Anne Hathaway, Jessica Chastain, Bill Irwin, Ellen Burstyn, Matt Damon, and Michael Caine. Set in a dystopian future where humanity is struggling to survive, the film follows a group of astronauts who travel through a wormhole near Saturn in search of a new home for mankind. Brothers Christopher and Jonathan Nolan wrote the screenplay, which had its origins in a script Jonathan developed in 2007. Caltech theoretical physicist and 2017 Nobel laureate in Physics[4] Kip Thorne was an executive producer, acted as a scientific consultant, and wrote a tie-in book, The Science of Interstellar. Cinematographer Hoyte van Hoytema shot it on 35 mm movie film in the Panavision anamorphic format and IMAX 70 mm. Principal photography began in late 2013 and took place in Alberta, Iceland, and Los Angeles. Interstellar uses extensive practical and miniature effects and the company Double Negative created additional digital effects. Interstellar premiered on October 26, 2014, in Los Angeles. In the United States, it was first released on film stock, expanding to venues using digital projectors. The film had a worldwide gross over $677 million (and $773 million with subsequent re-releases), making it the tenth-highest grossing film of 2014. It received acclaim for its performances, direction, screenplay, musical score, visual effects, ambition, themes, and emotional weight. It has also received praise from many astronomers for its scientific accuracy and portrayal of theoretical astrophysics. Since its premiere, Interstellar gained a cult following,[5] and now is regarded by many sci-fi experts as one of the best science-fiction films of all time. Interstellar was nominated for five awards at the 87th Academy Awards, winning Best Visual Effects, and received numerous other accolades"""
Split into Chunks
1 2 3 4 5
texts = text.split('.')
# remove the /n for every sentence texts = [t.strip('\n') for t in texts] texts
['Interstellar is a 2014 epic science fiction film co-written, directed, and produced by Christopher Nolan',
'It stars Matthew McConaughey, Anne Hathaway, Jessica Chastain, Bill Irwin, Ellen Burstyn, Matt Damon, and Michael Caine',
'Set in a dystopian future where humanity is struggling to survive, the film follows a group of astronauts who travel through a wormhole near Saturn in search of a new home for mankind',
'Brothers Christopher and Jonathan Nolan wrote the screenplay, which had its origins in a script Jonathan developed in 2007',
'Caltech theoretical physicist and 2017 Nobel laureate in Physics[4] Kip Thorne was an executive producer, acted as a scientific consultant, and wrote a tie-in book, The Science of Interstellar',
'Cinematographer Hoyte van Hoytema shot it on 35 mm movie film in the Panavision anamorphic format and IMAX 70 mm',
'Principal photography began in late 2013 and took place in Alberta, Iceland, and Los Angeles',
'Interstellar uses extensive practical and miniature effects and the company Double Negative created additional digital effects',
'Interstellar premiered on October 26, 2014, in Los Angeles',
'In the United States, it was first released on film stock, expanding to venues using digital projectors',
'The film had a worldwide gross over $677 million (and $773 million with subsequent re-releases), making it the tenth-highest grossing film of 2014',
'It received acclaim for its performances, direction, screenplay, musical score, visual effects, ambition, themes, and emotional weight',
'It has also received praise from many astronomers for its scientific accuracy and portrayal of theoretical astrophysics',
' Since its premiere, Interstellar gained a cult following,[5] and now is regarded by many sci-fi experts as one of the best science-fiction films of all time',
'Interstellar was nominated for five awards at the 87th Academy Awards, winning Best Visual Effects, and received numerous other accolades']
# Get the query's embedding query_embed = co.embed(texts=[query]).embeddings
# Retrieve the nearest neighbors similar_item_ids = search_index.get_nns_by_vector(query_embed[0], 3, include_distances=True) # Format the results # similar_item_ids 返回的其实texts的index和distance results = pd.DataFrame(data={'texts': [texts[t] for t in similar_item_ids[0]], 'distance': similar_item_ids[1]})
# 创建json格式输出 json = [] for i inrange(len(similar_item_ids[0])): json.append({'text':texts[i],'distence':similar_item_ids[1][i]}) return results,json
1 2 3
query="How much did the film make?" result,json = search(query) result